Olá, colegas e instrutores!
Estou estudando sobre otimização de hiperparâmetros usando RandomizedSearchCV e tive uma dúvida importante sobre a prática de divisão dos dados antes do treinamento.
Em cursos anteriores, sempre foi enfatizado que, ao aplicar validação cruzada, devemos usar apenas os dados de treino (X_treino e y_treino) para evitar vazamento de informações. Isso porque o conjunto de teste deve permanecer completamente isolado até a avaliação final.
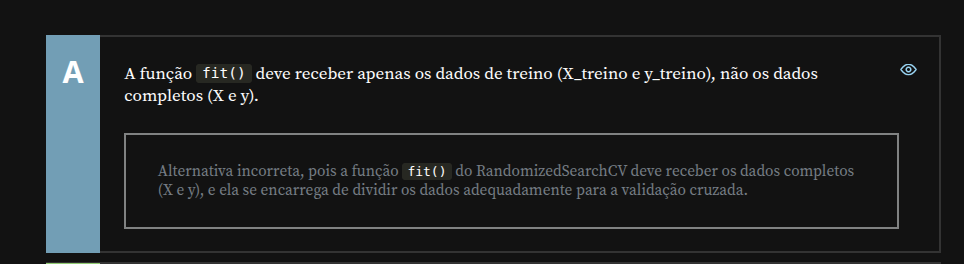
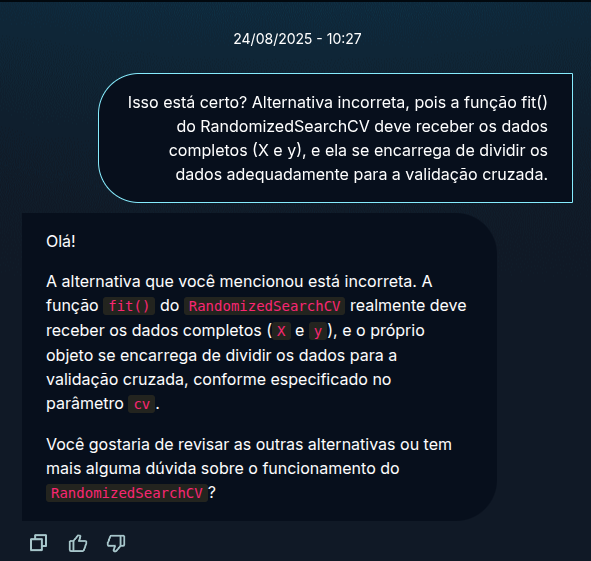
No entanto, na atividade atual, percebi que a função fit() do RandomizedSearchCV recebe o dataset completo (X e y), e a própria ferramenta realiza a divisão internamente para a validação cruzada. Ainda assim, a alternativa que afirma que "a função fit() deve receber apenas os dados de treino" foi marcada como incorreta, com a justificativa de que o RandomizedSearchCV cuida da divisão automaticamente.
Minha dúvida é:
É realmente correto enviar os dados completos (X e y) diretamente ao fit() do RandomizedSearchCV, mesmo que tenhamos um conjunto de teste separado?
Ou, apesar disso, ainda é uma boa prática separar previamente os dados em treino e teste, e passar apenas o treino para o RandomizedSearchCV, reservando o teste apenas para avaliação final?
Por exemplo:
# Opção 1: Usar dados completos
search = RandomizedSearchCV(modelo, param_distributions, cv=5)
search.fit(X, y) # X e y completos
# Opção 2: Separar antes
X_treino, X_teste, y_treino, y_teste = train_test_split(X, y, test_size=0.2)
search.fit(X_treino, y_treino) # Apenas treino
A primeira opção parece mais simples, mas existe risco de vazamento se o conjunto de teste estiver incluído nos dados usados para busca de hiperparâmetros?
Já vi explicações dizendo que o RandomizedSearchCV já faz a divisão interna e que não há problema, mas também leio que a separação prévia em treino/teste é essencial para garantir generalização.
Gostaria de entender qual é a prática recomendada nesse contexto, especialmente quando estamos trabalhando com modelos como XGBoost, onde a busca de hiperparâmetros pode ser computacionalmente intensiva.
Obrigado pela ajuda!