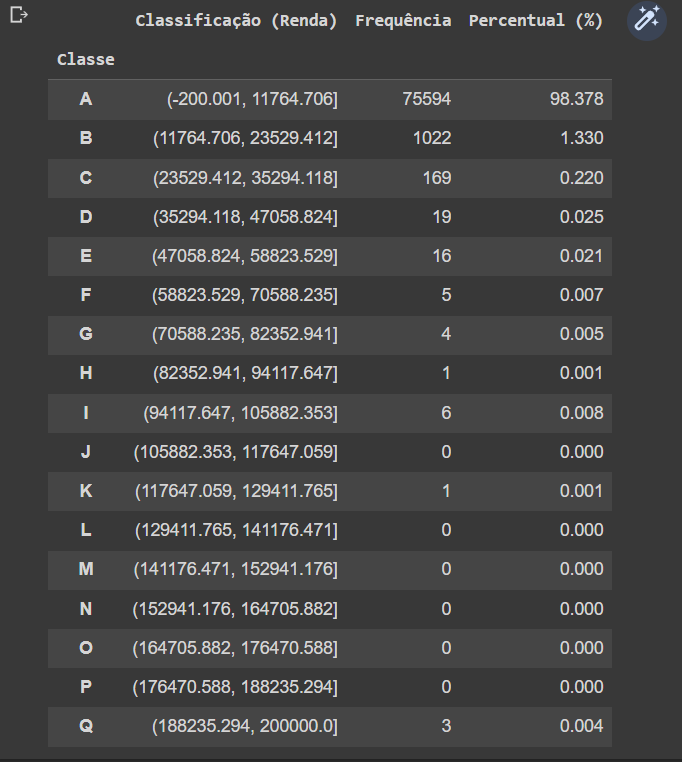
Nessa aula achei interessante os dados sobre cada classe, então decidi criar uma nova coluna já que estava sendo usada como índice. Os passos abaixo mostram como cheguei ao resultado que queria.
Passo 1: Criar uma lista para representar as 17 classes e ser o novo índice.
labels = ['A', 'B', 'C', 'D', 'E', 'F',
'G', 'H', 'I', 'J', 'K', 'L',
'M', 'N', 'O', 'P', 'Q']
idx = pd.Index(labels)Passo 2: Criar as variáveis 'Frequência' e 'Percentual'
frequencia = pd.value_counts(
pd.cut(x= dados['Renda'],
bins= 17,
include_lowest= True),
sort= False
)percentual = pd.value_counts(
pd.cut(x= dados['Renda'],
bins= 17,
include_lowest= True),
sort= False,
normalize= True).round(5) * 100Passo 3: Estilizando o nosso dataframe:
dist_freq = pd.DataFrame({'Frequência' : frequencia, 'Percentual (%)' : percentual})
dist_freq.reset_index(inplace=True)
dist_freq.set_index(idx, inplace= True)
dist_freq.index.name = 'Classe'
dist_freq.rename(columns= {'index' : 'Classificação (Renda)'}, inplace= True)
dist_freqO resultado foi esse: