Boas Vitor, tudo bem?
Espero que sim!
Vou mostrar a forma que eu acho mais eficiente de fazer isso.
Primeiramente, o seu código está excelente, parabéns!
Para Facilitar o processo, vou fazer uma alteração na criação do DataFrame:
tabela4 = pd.DataFrame({'Frequencia': freq4, 'Porcentagem %': porc4})
Dessa forma, nosso índice não terá nome, o que facilitará o reset mais tarde.
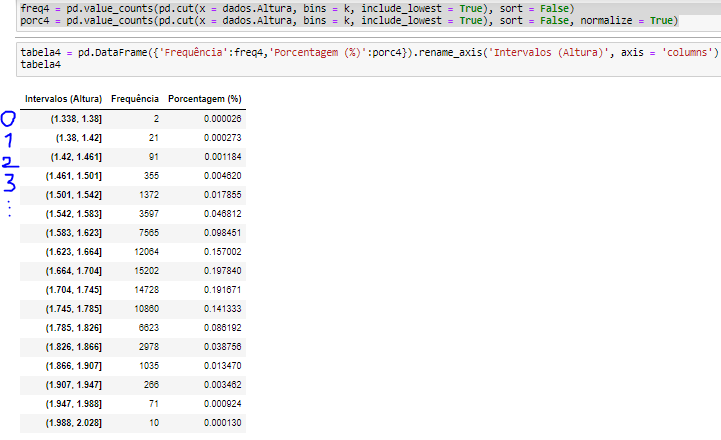
O Data Frame criado até então está assim:
Frequencia Porcentagem %
(1.338, 1.38] 2 0.000026
(1.38, 1.42] 21 0.000273
(1.42, 1.461] 91 0.001184
.... .. ...
Agora, vamos separar os intervalos de altura criando uma série a partir do índice atual:
intervalos_altura = pd.Series(tabela4.index)
Agora vaos adicionar esses valores como uma coluna do DataFrame:
tabela4['Intervalos Alturas'] = intervalos_altura.values
Nosso DataFrame agora está assim:
Frequencia Porcentagem % Intervalos Alturas
(1.338, 1.38] 2 0.000026 (1.338, 1.38]
(1.38, 1.42] 21 0.000273 (1.38, 1.42]
............ .. ........ ...........
Agora, vamos resetar o índice passando o parâmetro drop como true:
tabela_desejada = tabela4.reset_index(drop=True)
Agora, nosso Data Frame está assim:
Frequencia Porcentagem % Intervalos Alturas
0 2 0.000026 (1.338, 1.38]
1 21 0.000273 (1.38, 1.42]
2 91 0.001184 (1.42, 1.461]
3 355 0.004620 (1.461, 1.501]
4 1372 0.017855 (1.501, 1.542]
5 3597 0.046812 (1.542, 1.583]
Espero ter ajudado!
Bons estudos!