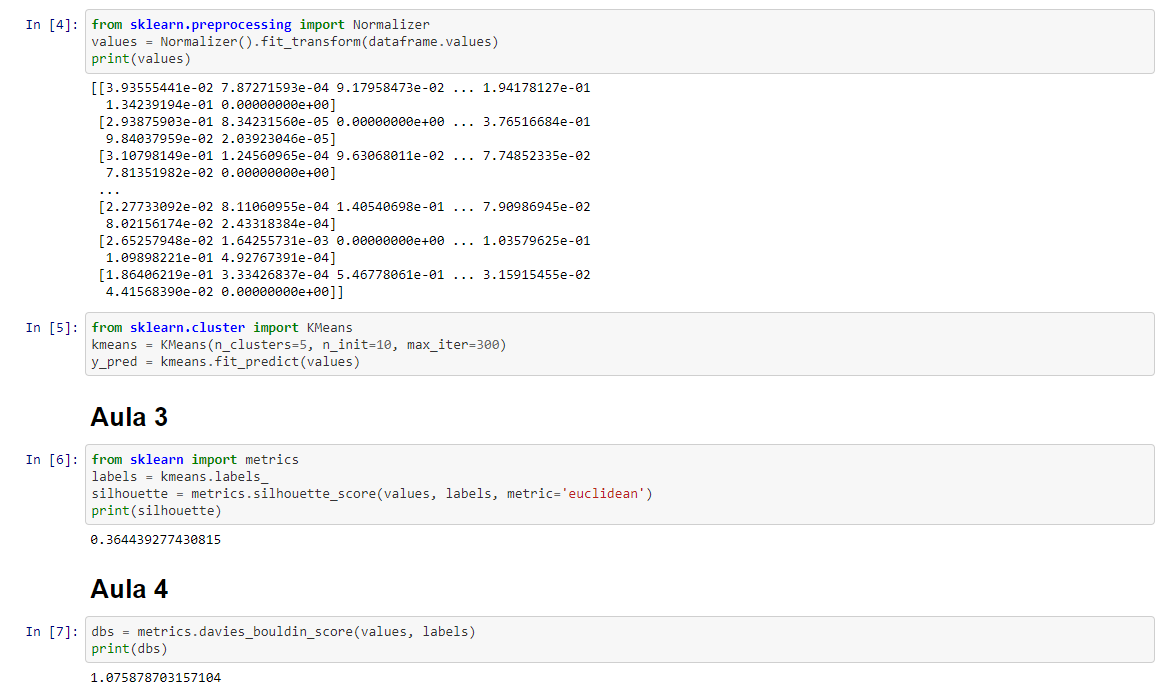
Olá! Fiquei com dúvida na forma em que os passos ocorreram. Por favor, observe a imagem abaixo: Na primeira linha, nós pegamos as variáveis e normalizamos elas (ok), depois chamamos o KMeans e associamos ele a uma variável chamada kmeans, que fará o processo de clusterização (até então, só passamos os parâmetros mas não executamos o cluster com nossos dados). Depois, criamos uma variável chamada y_pred que, de fato, faz o cluster dos nossos dados utilizando todas as variáveis que fornecemos. Então, tecnicamente, o y_pred que contém os clusters formados. Contudo, quando vamos criar as métricas de análise do cluster, chamamos labels = kmeans.labels_, mas não era y_pred que continha nosso cluster feito, com a indicação de qual dado foi para qual cluster? Em outros cursos, criavamos uma variável para fazer alguma predição, depois davamos .fit(database) nela e depois .labels_ nessa mesma variável. Por que dessa vez foi diferente? o kmeans contém o resultado do cluster mesmo este tendo sido associado a outra variável?
Obrigado