Oi, Rodrigo, tudo bem?
Desculpe a demora em te responder!
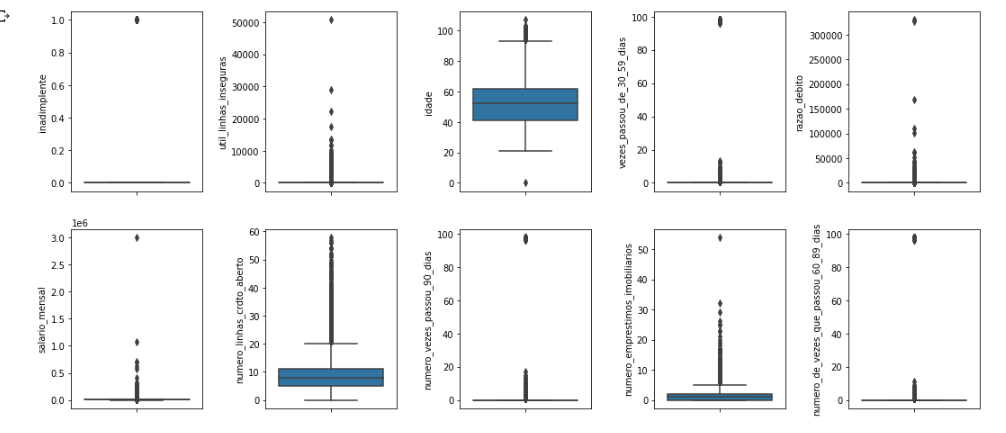
Lidar com outliers pode ser um desafio, especialmente quando os dados são únicos e muito dispersos. Contudo, há algumas estratégias que podem ser adotadas:
- Transformação de dados: você pode tentar transformar os dados para reduzir o impacto dos outliers. Por exemplo, a transformação logarítmica é uma técnica comum que pode ajudar a lidar com a dispersão dos dados.
- Binning: Outra opção é dividir os dados em "bins" ou categorias. Por exemplo, você poderia dividir a variável "salário" em categorias como "baixo", "médio" e "alto". Isso pode ajudar a reduzir a variância dos dados.
- Remoção de outliers: em alguns casos, pode ser justificável remover os outliers, especialmente se eles são devido a erros de medição ou entrada de dados. No entanto, esta deve ser uma última opção, pois os outliers podem conter informações importantes.
- Modelos robustos: alguns modelos de aprendizado de máquina são mais robustos a outliers do que outros. Por exemplo, modelos de árvore de decisão podem lidar bem com outliers, pois eles dividem o espaço de dados em regiões distintas.
Lembre-se, é importante entender a natureza dos seus outliers e o impacto que eles têm no seu modelo antes de decidir como lidar com eles.
Espero ter ajudado. Caso tenha dúvidas, não hesite em postar no fórum!
Abraços e bons estudos!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!