Olá, tenho um dataframe com uma coluna do tipo datetime, neste formato: 2020-02-13 10:55:00 e gostaria de agrupar meus dados por HORA do dia. Como fazer isso de forma mais inteligente?
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Olá, tenho um dataframe com uma coluna do tipo datetime, neste formato: 2020-02-13 10:55:00 e gostaria de agrupar meus dados por HORA do dia. Como fazer isso de forma mais inteligente?


Olá Somali! Como está?
Peço desculpas pela demora em dar um retorno.
Uma forma de fazer esse agrupamento seria utilizando o método groupby e uma função lambda para conseguir acessar apenas as horas da sua coluna. Vamos fazer um exemplo para entendermos como esse processo pode ser feito.
Para o exemplo, vou utilizar o seguinte dataframe:
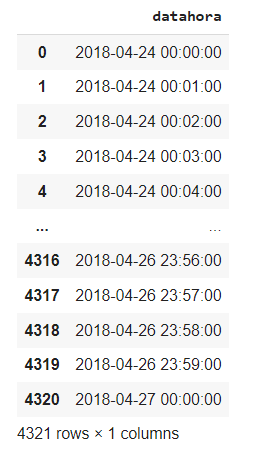
A coluna datahora está no formato datetime. Para agrupar meus dados pela hora e fazer a contagem de vezes que cada hora aparece, posso fazer o seguinte:
grp = df.groupby(by = [df.datahora.map(lambda x: (x.hour, x.minute))])
grp.count()Nessa primeira linha, a função lambda está percorrendo a coluna de datahora e pegando apenas as horas e os minutos. Daí, por meio do método groupby, o dataframe está sendo agrupado de acordo com as horas e minutos. E na linha seguinte a função count é responsável por contar quantas vezes cada hora e minuto aparece.
Dessa forma, teremos o resultado:

Onde essa primeira coluna mostra os valores da hora e minutos, no seguinte formato: (horas, minutos) e a segunda coluna mostra quantas vezes cada uma dessas horas/minutos aparecem. Para mudar os nomes dessas colunas você pode fazer o seguinte:
df_agrupado = pd.DataFrame(grp.count())
df_agrupado.index.name = 'Hora/Minuto'
df_agrupado.columns = ['Frequência']Outra forma de fazer, também, é divididindo as horas e minutos em colunas distintas, da seguinte forma:
grp = df.groupby(by = [df.datahora.map(lambda x: x.hour),
df.datahora.map(lambda x: x.minute)])
grp.count()No qual o resultado seria:
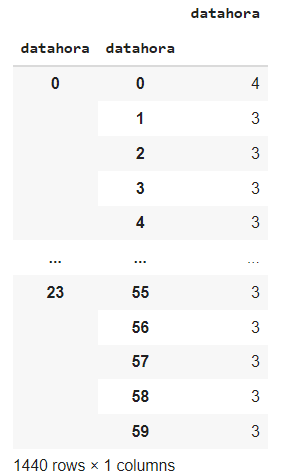
E para mudar os nomes dessas colunas você pode fazer o seguinte:
df_agrupado = pd.DataFrame(grp.count())
df_agrupado.columns = ['Frequência']
df_agrupado.index.names = ['Horas', 'Minutos']Espero que isso te ajude!
Caso queira testar com o dataframe que utilizei no exemplo, vou deixar o código dele aqui:
index = pd.date_range(start='2018-04-24', end='2018-04-27', freq='T')
df = pd.DataFrame(range(len(index)), index=index).reset_index()
df.drop(0, axis=1, inplace=True)
df.columns = ['datahora']Se ficar com alguma dúvida estou por aqui :)
Bons estudos!