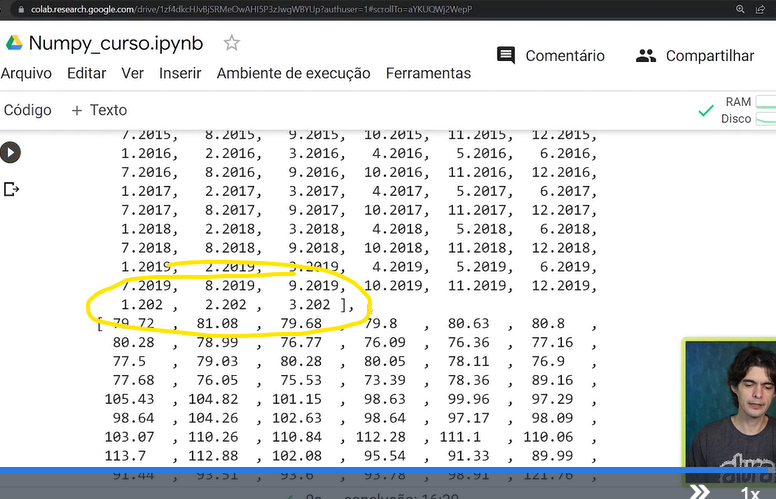
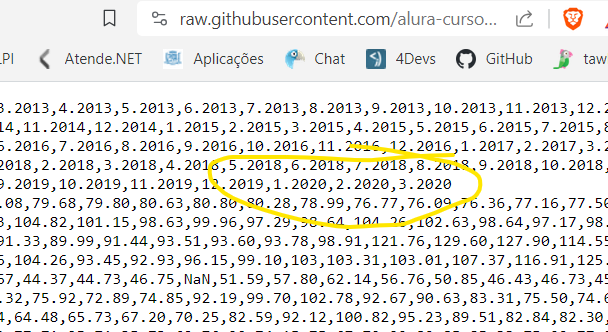
Já descobri o problema, não é um BUG e sim uma característica do próprio NumPy.
Como o professor indicou, o NumPy trabalha somente com um dataset completo, com o mesmo tipo de dados.
Nesse caso, ele reconhece os dados como float.
E em um dado float, o zero à direita do ponto é irrelevante, os registros (1.2020, 2.2020 e 3.2020) acabam perdendo esse último zero.
Para contornar o problema, é possível forçar o NumPy a criar o dataset como string:
url = 'https://raw.githubusercontent.com/alura-cursos/numpy/dados/apples_ts.csv'
# Carregar os dados para o NumPy como strings
dados = np.loadtxt(url, delimiter=',', usecols=np.arange(80, 88), dtype=str)
print(dados)
Porém, obviamente isso gera um monte de outros problemas para frente.... na hora de fazer os cálculos.
Enfim, aprendi que o ideal para o NumPy é usar apenas dados mesmo, sem índices.
Se precisar de índices, o mais indicado é usar o Pandas.