
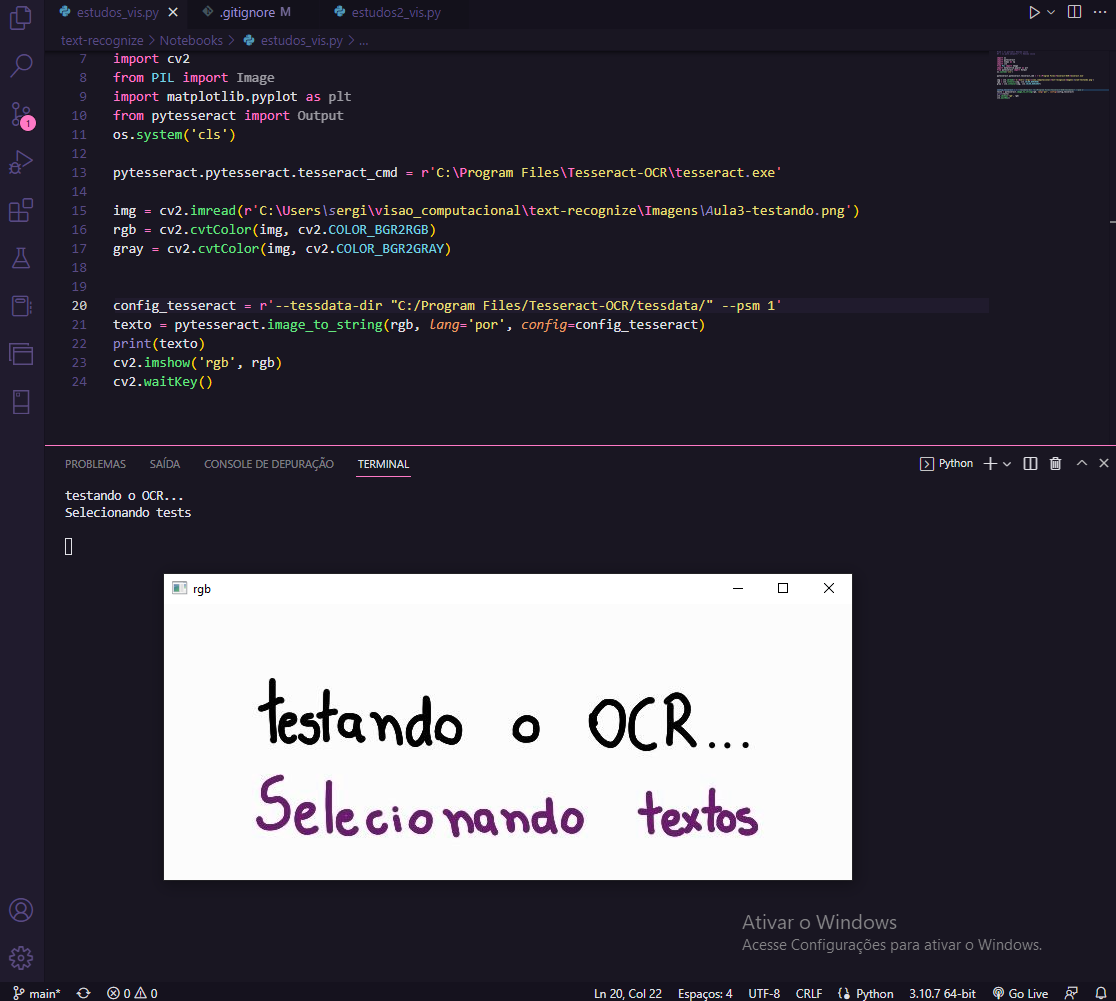
Em uma aula do curso Visão Computacional: reconhecimento de texto com OCR e OpenCV, segui todos os passos do exemplo e ainda assim a leitura sai diferente do q foi mostrado, gostaria de saber se tem como melhorar o desempenho e assertividade de alguma forma, testei com outros psm's e cores, e o resultado foi o mesmo. [foto do código e da imagem que está sendo lida pelo programa]!(https://cdn1.gnarususercontent.com.br/1/1323203/0913947f-30cb-44ab-a68a-9899f9c731e2.png)


{kind=link}