O professor usa o seguinte código para transformar algumas colunas do dataframe "dataset" de string para double:
dataset\
.withColumn('usableAreas', dataset['usableAreas'].cast(IntegerType()))\
.withColumn('price', dataset['price'].cast(DoubleType()))\
.withColumn('condo', dataset['condo'].cast(DoubleType()))\
.withColumn('iptu', dataset['iptu'].cast(DoubleType()))\
.printSchema()
E quando eu uso o dataset.printSchema ele mostra que realmente viraram double, porém quando eu uso dataset.show( ) a aparência das linhas das colunas que são double ficam como se fossem int:
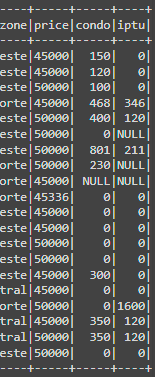
O que será que está acontecendo? Eu tentei criar novas colunas baseadas nessas colunas e usei a função round, e aí deu certo, porém depois eu não consigo deletar as colunas antigas para ficar com as colunas novas. Quando uso a função dataset.drop("coluna"), ele dá o seguinte erro:
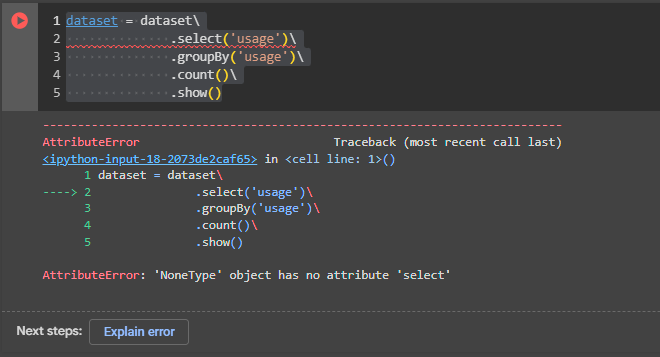
AttributeError: 'NoneType' object has no attribute 'drop'