
Olá, estava fazendo o projeto do curso: Machine learning: Introdução a classificação SKLearn Aula 03 - Um projeto de baixa dimensionalidade e o baseline Video 03 - Testando em duas dimensões.
Quando estava fazendo a parte final rodando o código com o treino, teste, modelo previsões e acurácia, aconteceram duas coisas diferentes do mostrado em vídeo:
Ps.: ESTAVA UTILIZANDO O JUPYTER E DEPOIS FIZ NO COLAB E DERAM OS MESMOS ERROS.
CÓDIGO:
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
SEED = 20
treino_x, teste_x, treino_y, teste_y = train_test_split(x, y, random_state = SEED, test_size = 0.25, stratify = y)
print('Testaremos com %d elementos e treinaremos com %d elementos' % (len(treino_x), (len(teste_x))))
modelo = LinearSVC()
modelo.fit(treino_x, treino_y)
previsoes = modelo.predict(teste_x)
acuracia = accuracy_score(teste_y, previsoes)*100
print('A acurácia foi %.2f%%' %acuracia)
ERROS: 1) Apareceu a msg em vermelho conforme print que não aparece na aula 2) Mudou a acurácia: nota-se que a acurácia é de 65,93% porém se eu rodar o código novamente a acurácia também muda, mesmo com a SEED sendo informada.
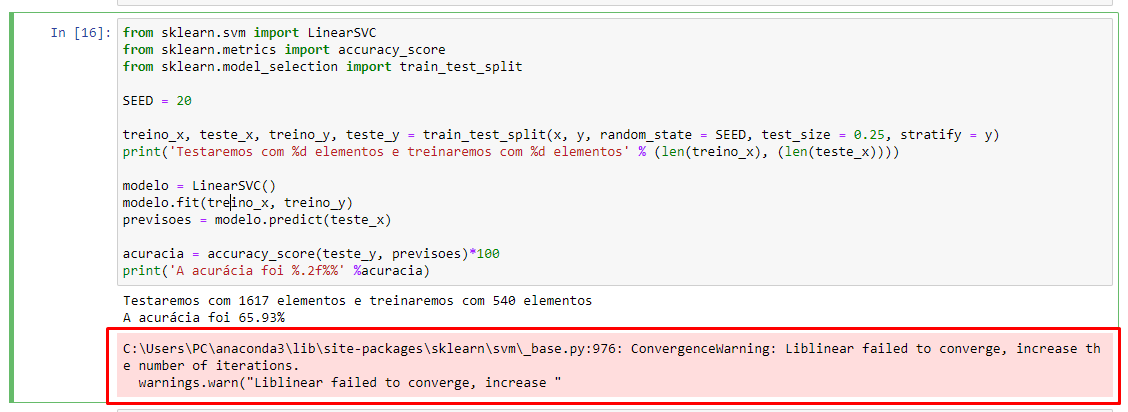
SE RODAR NOVAMENTE, MUDA-SE A ACURÁCIA:
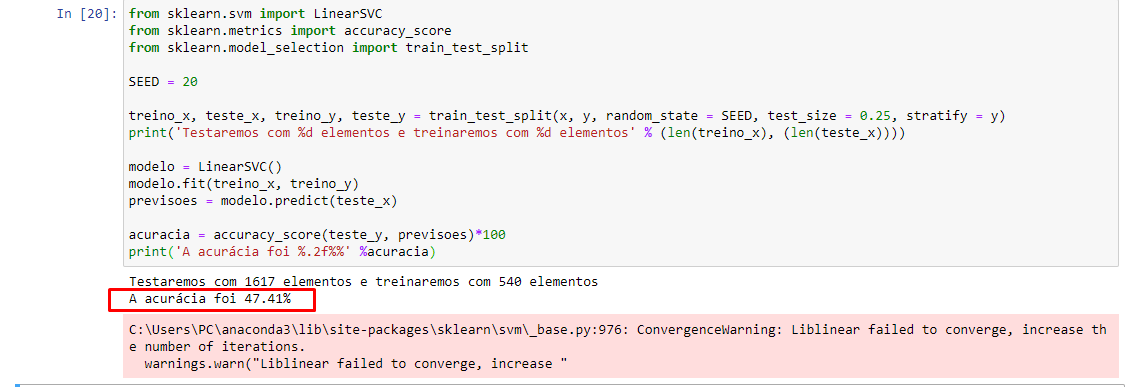
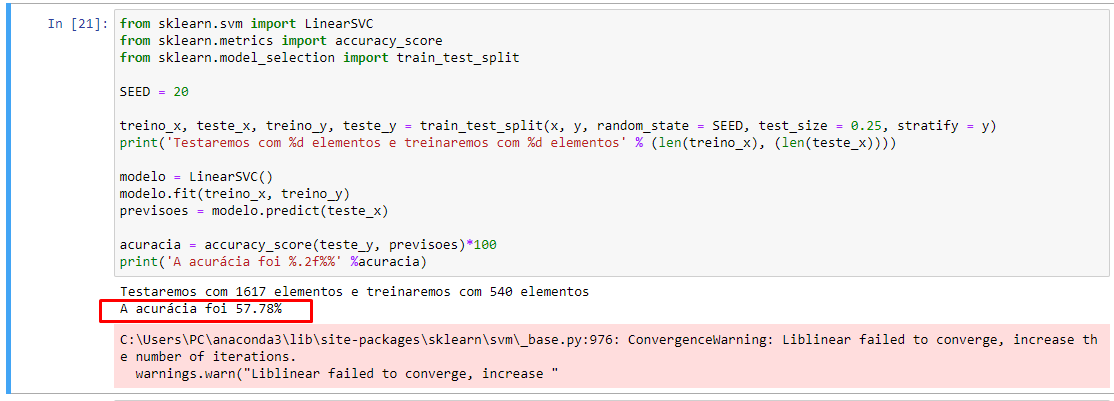 O que pode estar ocorrendo?
O que pode estar ocorrendo?
