Olá, fiquei com dúvida em um ponto.
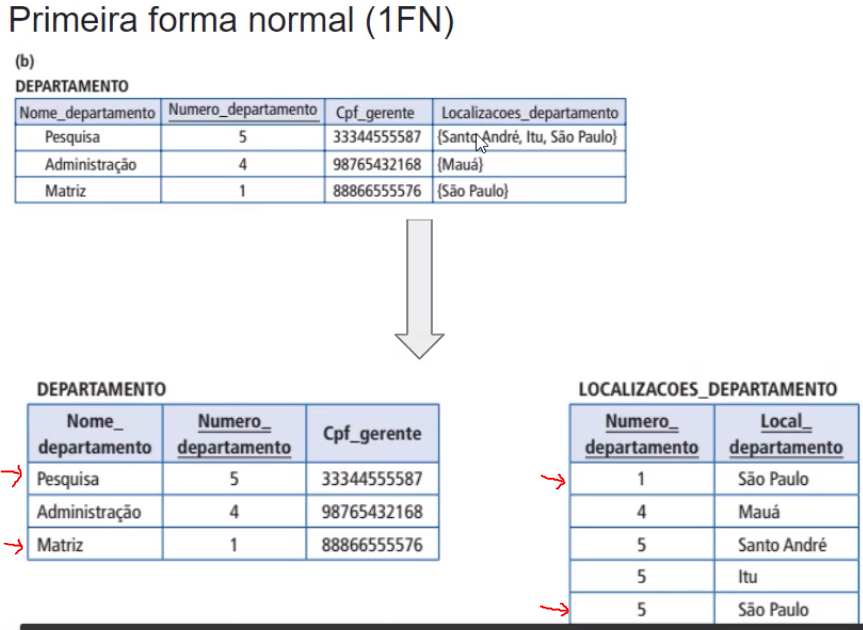
Quando o professor explica sobre a primeira regra de normalização (1FN), ela mostra um exemplo de decomposição da relação, onde a tabela Departamento se divide em duas outras (Departamento e Localizacoes_Departamento). Nessa segunda tabela, para um mesmo Numero_Departamento eu acabo tendo três diferentes classificações para o número 5 que são Santo André, Itu e São Paulo para Local_Departamento.
Por mais que tenha acontecido a "divisão", e que a tabela de Departamento não tenha mais o atributo composto contendo as três classificações num mesmo campo, quando eu for criar a relação (join) entre as tabelas Departamento e Localizacoes_Departamento na prática, eu vou gerar a mesma redundância que é exemplificado quando o professor mostra a quebra em linhas de Departamento , ao invés de duas tabelas.
Gostaria de entender a diferença entre os dois tipos de normalização acima citados, e saber porque o primeiro de decomposição não acaba sendo classificado como redundante também, uma vez que ele continuará tendo três classificações distintas para um mesmo item (5) e isso estará explícito quando eu criar relações (joins).
Obrigado desde já!
Abraços, Mathaus.